蒙地卡罗方法求 PI
2013-11-16
蒙特卡罗方法
蒙特卡罗方法(Monte Carlo method),也称统计模拟方法,是二十世纪四十年代中期由于科学技术的发展和电子计算机的发明,而被提出的一种以概率统计理论为指导的一类非常重要的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法1。
求 PI
假设有一个圆半径为1,那么四分之一圆面积就为 $\frac{\pi}{4}$,而包括此四分之一圆的正方形面积就为1,如下图1:
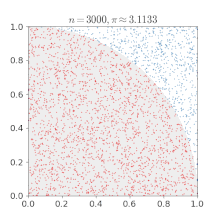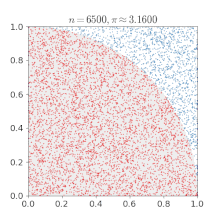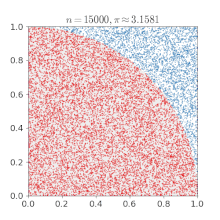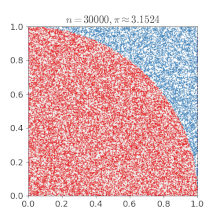
如果随意的在正方形中投点,坐标为 $x, y$, 则这些点有些会落于四分之一圆内,假设所投射的点有 m 点,在圆内的点有 n 点,则 $\frac{n}{m}\times4=\pi$,如果 $x, y$满足 $x^2 + y^2 \leq 1$ 则该点落在了圆内。
代码2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#include <string.h>
#define SEED 35791246
main(int argc, char* argv){
int niter=0;
double x,y;
int i,count=0; /* # of points in the 1st quadrant of unit circle */
double z;
double pi;
printf("Enter the number of iterations used to estimate pi: ");
scanf("%d",&niter);
/* initialize random numbers */
srand(SEED);
count=0;
for ( i=0; i<niter; i++) {
x = (double)rand()/RAND_MAX;
y = (double)rand()/RAND_MAX;
z = x*x+y*y;
if (z<=1) count++;
}
pi=(double)count/niter*4;
printf("# of trials= %d , estimate of pi is %g \n",niter,pi);
}
如果将上述代码中的 SEED 用 time 函数替代,每次同样的 niter 都会得到不同的结果。 取 10000 的三次结果:
# of trials= 10000 , estimate of pi is 3.1388 # of trials= 10000 , estimate of pi is 3.1552 # of trials= 10000 , estimate of pi is 3.1468 # of trials= 10000 , estimate of pi is 3.1224 # of trials= 1000000 , estimate of pi is 3.14172 # of trials= 1000000 , estimate of pi is 3.14066 # of trials= 1000000 , estimate of pi is 3.14018
如果不是用随机落点的方式,而是对这个正方形进行从有限到无穷的切割成小正方形,每一个小正方形视为一个点则有下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char *argv[]){
time_t start, end;
int R = atoi(argv[1]);
unsigned long R2 = R * R;
time(&start);
unsigned long x, y;
unsigned long total = 0, miss = 0;
unsigned long y2[R];
unsigned long x2;
for(y = 0; y < R; y++){
y2[(int)y] = y * y;
}
for (x = 0; x < R; x++){
x2 = x * x;
for(y = 0; y < R; y++){
total++;
if(x2 + y2[(int)y] > R2){
miss++;
}
}
}
time(&end);
printf("R = %d\tPI = %f\ttime consume:%f\n", R, (double)4 * (total - miss) / total, difftime(end, start));
return 0;
}
测试结果:
R = 10 PI = 3.520000 time consume:0.000000 R = 100 PI = 3.181200 time consume:0.000000 R = 1000 PI = 3.145544 time consume:0.000000 R = 10000 PI = 3.141990 time consume:1.000000 R = 30000 PI = 3.141726 time consume:4.000000 R = 40000 PI = 3.141692 time consume:8.000000
如果不计算随机数生成的消耗,第一种方法的复杂度是 $O(n)$,而后一种的是 $O(n^2)$. 第一种利用了随机生成器提高了运行效率,同时也降低了精度(即使取10的9次方个随机点时,其结果也仅在前4位与圆周率吻合1)。第一种算法取100万级的数压力也不算大,第二种取到10万已经很囧了。但是后一种算法对于人来说和随机的方法没什么区别,如果有足够的耐心,用手也可以求出精度较高 $\pi$ 值;-)
blog comments powered by Disqus